Starglider wrote:Sikon wrote:In contrast, a lot of sci-fi depicts the first sapient AI as more or less the equivalent of a brain in a box: a computer without any avatar body, imagined to have sapience just through pre-programming rather than gradually obtaining such through learning.
Brain in a box, yes. Completely pre-programmed with no learning is quite uncommon though.
Sapient computers in popular sci-fi are depicted as capable of learning after creation. However, they tend to be shown as sapient from the moment of activation, just pre-programmed into sapience rather than gaining sapience through learning, even if the first of their kind. For example, HAL and M-5 weren't shown as gaining sapience from learning over time like the progression from a human baby to an adult but rather were shown as full-fledged sapients from the moment of their introduction in the movie
2001: A Space Odyssey and the
Star Trek episode
The Ultimate Computer respectively. (I enjoyed watching both, but that doesn't affect my point about the prevailing depiction of sapient AIs).
No offense, but you seem to be nitpicking too much here.
Starglider wrote:However a great deal of learning is possible without needing any sort of embodiment, physical or even VR-type simulation, via scanning of existing electronic material and use of internal modelling.
[...]
Interacting with the environment is actually pretty worthless for the 'sapience' part. All it will do is improve motor skills (which are a conventional engineering problem more than an AI problem at this point) and develop the self-environment embedding model, which is something evolutionary methods have a big problem with but is actually pretty straightforward to design in de novo.
A "great deal of learning" being possible through that alone is technically true. However, obtaining sapience would be challenging enough without unnecessary constraints on a learning AI having no physical embodiment to interact with the real-world environment. If the goal is to do it as fast and easily as possible, one is likely better off with a physical avatar.
One method is suggested by analogy with a human baby:
For example, a baby's brain may try various actions, such as making various speech sounds after hearing them. A little analogous to
genetic programming, when a technique results in success as measured by the internal goal system, that method is reinforced and more probable to be tried again. In this example, the baby pronouncing various sounds may eventually pronounce "mommy," which may be rewarded by attention, physical contact, or food, leading to learning, where the baby is starting to properly pronounce a word while associating it with a result. Hour by hour, day by day, year by year, the complexity of useful "programming" in the brain increases ... not just motor skills but general knowledge on every random topic. There's all sorts of little things learned over time, too many for any human to consciously remember and list them all, let alone directly program all aspects of them into electronic media in a reasonable period of time.
Of course, an AI doesn't have to learn in exactly the same manner, but the general idea of learning with a physical avatar can have greater practical potential than trying to encode "common sense" about the real world into electronic material directly. Implementing the latter with software has historically been rather limited. For example, recent computer game software sometimes tries to have more of a "physics model"
system, but even that created with thousands of manhours of coding is lousy compared to the complexity of the real world.
There's limits even to the information available from all electronic media and from all the books in all the world's libraries combined. A million manhours of effort could still overlook much, when so much of the thought patterns in human sapience didn't come from any publication's instructions.
Given an astronomically complex and sufficiently perfect virtual reality simulation, an AI could theoretically learn enough to reach sapience without a physical avatar interacting with the real world. But such would have little to do with what is most reasonable for the first sapient AI's development succeeding in the easiest manner. Virtual simulations of today are like at the level illustrated by computer games, not even remotely close to suitable. For example, the virtual environment of a few gigabyte computer game is nothing in comparison to the complexity of the real world. While of course such will improve in the future, it would tend to take far more manhours to try to encode a sufficiently complete virtual reality simulation (if even possible in any reasonable amount of time) than just to build a physical avatar body for the learning AI.
Starglider wrote:Sikon wrote:Without interaction with the environment prior to full-fledged sapience and without gradual learning like that of a human baby and child, such implicitly is assuming human programmers somehow manage to encode "from scratch" the equivalent of the ~ 1E15 bit complexity of a sapient human brain.
You can't compare information encoded in neuron structure to lines of code. NNs have ok though highly lossy compression for media information, but sucky compression on causal complexity and have to use massive redundancy to implement reasonably reliable/lossless storage.
The estimate isn't exact to multiple significant figures or anything silly like that, but one certainly can tell that there's an astronomical amount of data involved in the sapient human brain. Such is known to a degree sufficient for my point about the orders of magnitude difference between it and the relatively small amount of brain structure information encoded in DNA.
A 1998 article by Moravec is relevant here:
When Will Computer Hardware Match the Human Brain, Journal of Evolution and Technology wrote:Computers have far to go to match human strengths, and our estimates will depend on analogy and extrapolation. Fortunately, these are grounded in the first bit of the journey, now behind us. Thirty years of computer vision reveals that 1 MIPS can extract simple features from real-time imagery--tracking a white line or a white spot on a mottled background. 10 MIPS can follow complex gray-scale patches--as smart bombs, cruise missiles and early self-driving vans attest. 100 MIPS can follow moderately unpredictable features like roads--as recent long NAVLAB trips demonstrate. 1,000 MIPS will be adequate for coarse-grained three-dimensional spatial awareness--illustrated by several mid-resolution stereoscopic vision programs, including my own. 10,000 MIPS can find three-dimensional objects in clutter--suggested by several "bin-picking" and high-resolution stereo-vision demonstrations, which accomplish the task in an hour or so at 10 MIPS. The data fades there--research careers are too short, and computer memories too small, for significantly more elaborate experiments.
There are considerations other than sheer scale. At 1 MIPS the best results come from finely hand-crafted programs that distill sensor data with utmost efficiency. 100-MIPS processes weigh their inputs against a wide range of hypotheses, with many parameters, that learning programs adjust better than the overburdened programmers. Learning of all sorts will be increasingly important as computer power and robot programs grow. This effect is evident in related areas. At the close of the 1980s, as widely available computers reached 10 MIPS, good optical character reading (OCR) programs, able to read most printed and typewritten text, began to appear. They used hand-constructed "feature detectors" for parts of letter shapes, with very little learning. As computer power passed 100 MIPS, trainable OCR programs appeared that could learn unusual typestyles from examples, and the latest and best programs learn their entire data sets. Handwriting recognizers, used by the Post Office to sort mail, and in computers, notably Apple's Newton, have followed a similar path. Speech recognition also fits the model. Under the direction of Raj Reddy, who began his research at Stanford in the 1960s, Carnegie Mellon has led in computer transcription of continuous spoken speech. In 1992 Reddy's group demonstrated a program called Sphinx II on a 15-MIPS workstation with 100 MIPS of specialized signal-processing circuitry. Sphinx II was able to deal with arbitrary English speakers using a several-thousand-word vocabulary. The system's word detectors, encoded in statistical structures known as Markov tables, were shaped by an automatic learning process that digested hundreds of hours of spoken examples from thousands of Carnegie Mellon volunteers enticed by rewards of pizza and ice cream. Several practical voice-control and dictation systems are sold for personal computers today, and some heavy users are substituting larynx for wrist damage.
More computer power is needed to reach human performance, but how much? Human and animal brain sizes imply an answer, if we can relate nerve volume to computation. Structurally and functionally, one of the best understood neural assemblies is the retina of the vertebrate eye. Happily, similar operations have been developed for robot vision, handing us a rough conversion factor.
[...]The retina is a transparent, paper-thin layer of nerve tissue at the back of the eyeball on which the eye's lens projects an image of the world. It is connected by the optic nerve, a million-fiber cable, to regions deep in the brain. It is a part of the brain convenient for study, even in living animals because of its peripheral location and because its function is straightforward compared with the brain's other mysteries. A human retina is less than a centimeter square and a half-millimeter thick. It has about 100 million neurons, of five distinct kinds. Light-sensitive cells feed wide spanning horizontal cells and narrower bipolar cells, which are interconnected by whose outgoing fibers bundle to form the optic nerve. Each of the million ganglion-cell axons carries signals from a amacrine cells, and finally ganglion cells, particular patch of image, indicating light intensity differences over space or time: a million edge and motion detections. Overall, the retina seems to process about ten one-million-point images per second.
It takes robot vision programs about 100 computer instructions to derive single edge or motion detections from comparable video images. 100 million instructions are needed to do a million detections, and 1,000 MIPS to repeat them ten times per second to match the retina.
The 1,500 cubic centimeter human brain is about 100,000 times as large as the retina, suggesting that matching overall human behavior will take about 100 million MIPS of computer power.
[...]If 100 million MIPS could do the job of the human brain's 100 billion neurons, then one neuron is worth about 1/1,000 MIPS, i.e., 1,000 instructions per second. That's probably not enough to simulate an actual neuron, which can produce 1,000 finely timed pulses per second. Our estimate is for very efficient programs that imitate the aggregate function of thousand-neuron assemblies. Almost all nervous systems contain subassemblies that big.
The small nervous systems of insects and other invertebrates seem to be hardwired from birth, each neuron having its own special predetermined links and function. The few-hundred-million-bit insect genome is enough to specify connections of each of their hundred thousand neurons. Humans, on the other hand, have 100 billion neurons, but only a few billion bits of genome. The human brain seems to consist largely of regular structures whose neurons are trimmed away as skills are learned, like featureless marble blocks chiseled into individual sculptures. Analogously, robot programs were precisely hand-coded when they occupied only a few hundred thousand bytes of memory. Now that they've grown to tens of millions of bytes, most of their content is learned from example.
[...]Programs need memory as well as processing speed to do their work. The ratio of memory to speed has remained constant during computing history. The earliest electronic computers had a few thousand bytes of memory and could do a few thousand calculations per second. Medium computers of 1980 had a million bytes of memory and did a million calculations per second. Supercomputers in 1990 did a billion calculations per second and had a billion bytes of memory. The latest, greatest supercomputers can do a trillion calculations per second and can have a trillion bytes of memory. Dividing memory by speed defines a "time constant," roughly how long it takes the computer to run once through its memory. One megabyte per MIPS gives one second, a nice human interval.
[...]The best evidence about nervous system memory puts most of it in the synapses connecting the neurons. Molecular adjustments allow synapses to be in a number of distinguishable states, lets say one byte's worth. Then the 100-trillion-synapse brain would hold the equivalent 100 million megabytes. This agrees with our earlier estimate that it would take 100 million MIPS to mimic the brain's function. The megabyte/MIPS ratio seems to hold for nervous systems too! The contingency is the other way around: computers are configured to interact at human time scales, and robots interacting with humans seem also to be best at that ratio.
[...]With our conversions, a 100-MIPS robot, for instance Navlab, has mental power similar to a 100,000-neuron housefly. The following figure rates various entities.
From here.
Estimates vary a bit, such as by plus or minus one or two orders of magnitude, like for this article versus others, but the important thing is that it is easily millions of megabytes as opposed to any small figure like a few megabytes. Indeed, the difference between sapient human brain complexity versus starting DNA data is definitely large enough with your estimate of 30 megabytes for brain structure encoding in human DNA.

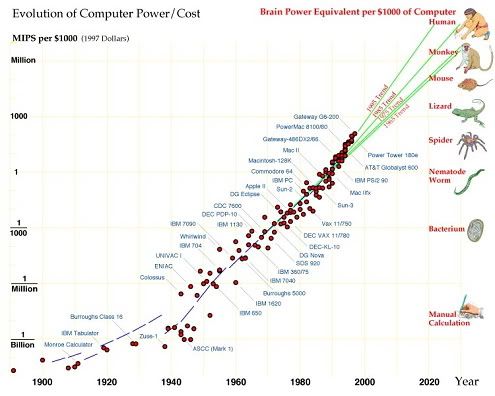
The above is a good illustration of insufficient hardware today still being one limit but with a point perhaps fast approaching where software progress lagging behind hardware progress may become the primary issue.
Starglider wrote:it would only be plausible for an AI built incrementally by a huge army of programmers, probably a whole industry
If human-level AI is eventually developed in a given timeframe, chances of success would tend to be better with $10 billion, $100 billion, or $1 trillion spent over the years than with a project employing a small number of people and a millionth as much. While it's hard to be sure of success occurring in a given timeframe even with large funds, chances would tend to be better than with a small project.
For example, a small number of programmers may within several years of effort code a computer game of today including its very primitive AI, but human-level AI is so many orders of magnitude different, trying to manage what would be the greatest engineering accomplishment in history.
Of course, to some degree, many small groups of researchers in aggregate may amount to the equivalent of a large army of programmers over the decades, sharing information and building upon each other's work, perhaps eventually obtaining the equivalent of a vast project despite individually small efforts. There should be incremental progress beyond current robots that tend to be around insect-level.
Starglider wrote:But of course the vast majority of complexity in a human brain is not code-equivalent (or at least, not the kind of high level structure a human would write). The DNA specifying brain function (at a rough guess, probably around 30 megabytes) is a much closer analogy to AI code, and that's still a lot bigger than most envisioned AGI code (but not knowledge) bases.
That may be very true for what's theoretically possible. Given sufficiently optimized perfect programming like that which superhuman AIs could manage, equal or greater efficiency than the biological seed code is undoubtedly possible. However, one would have to be hesitant to assume the human-written seed code for the first sapient AI would be that optimized and that efficient. DNA's coding is shockingly efficient for what it accomplishes relative to human programmers when 30 megabytes is what just AcroRd32.exe (Acrobat PDF file reader) takes in memory.
Starglider wrote:For the 'sapience' part you'd need lots of social interaction and language use. Having a physical body isn't really necessary or even useful for this. In particular you wouldn't want to lumber an AI with the ridiculously narrow bandwidth of a single sensorium when with adequate CPU it can analyse thousands of video streams and conversations, play competitive-negotiation games with subinstances of itself, hold hundreds of IM conversations with humans etc.
A sufficiently powerful and advanced AI could handle millions, billions, or more avatar bodies or other sources and recipients of data at once.
However, it may be easier to first develop an AI that can handle one body with sapient-level intelligence, following the
general KISS principle of engineering. (Actually, it might be easiest to do it very incrementally, such as first managing the equivalent of a lizard's general intelligence then progressively greater challenges, breaking a hard problem down into smaller steps to be mastered one at a time before focusing on the next). When the AI becomes powerful enough in time, it can always control more avatars and have more incoming sources of data later.
Starglider wrote:Sikon wrote:Possibly, there might be additional similarities to biological brain development for the first sapient AI if its seed code was developed by understanding and partially copying that of progressively more complex biological organisms, from those with simple nervous systems to those with complex brains
Well yes, if you mimic biology closely, then your learning process /will/ resemble biological learning. I don't personally like the biomorphic approach, but I admitt that the consequences of a /badly written/ biomorphic AGI have a significantly smaller chance of being disasterous that a /badly written/ de novo AGI.
That's a good point. In fact, if the first sapient AI was simply raised to human-level brainpower and operating speed before proceeding further, while resembling biological intelligence enough to be (relatively) understood by humans, that could be a powerful safeguard. In that case, only upon passing a safety evaluation would it be subsequently cleared to receive continuing upgrades taking it to the less understandable, harder to predict, more alien state of superhuman intelligence. A primitive analogy is that those in sensitive military positions like personnel handling nuclear weapons are given psych screening first.
Starglider wrote:Sikon wrote:Of course, after that, things get more complicated, as potentially sapient AIs may become more and more alien.
Of course they will, but if they're transhumand and they're actually interested in communicating with you then you may not notice, as emulating a human personality at the interface layer will rapidly become a trivial task.
True ... though there might also be obtained the technology to upgrade one's own intelligence, reducing the gap.
Starglider wrote:While a large minority of AGI researchers believe that embodiment makes things much easier regardless of whether the AI is closely biomorphic (obviously I am not in this group), only a small minority claim that embodiment is absolutely necessary in the development of a new AI.
When current robots don't compare well in versatile intelligence even to lizards, with progress slowed by software limitations even when hardware capabilities improve, any technique that makes it much easier to transverse the vast gap to human and superhuman intelligence in a reasonable period of time is practically a necessity. Obtaining such would be hard enough without unnecessary constraints on the solution like skipping the benefit of having a physical avatar body through which the AI learns from interaction with the real world.





